BFS og DFS er de krydsende metoder, der bruges til at søge en graf. Grafstregning er processen med at besøge alle knudepunkterne i grafen. En graf er en gruppe af Vertices 'V' og Edges 'E', der forbinder til hjørnerne.
Sammenligningstabel
| Grundlag for sammenligning | BFS | DFS |
|---|---|---|
| Grundlæggende | Vertex-baseret algoritme | Edge-baseret algoritme |
| Datastruktur bruges til at gemme noderne | Kø | Stak |
| Hukommelsesforbrug | ineffektiv | Effektiv |
| Strukturen af det konstruerede træ | Bred og kort | Smal og lang |
| Traversing mode | Ældste uvisse hjørner udforskes først. | Skråninger langs kanten udforskes i begyndelsen. |
| optimalitet | Optimal til at finde den korteste afstand, ikke i pris. | Ikke optimalt |
| Ansøgning | Undersøger todelt graf, tilsluttet komponent og korteste vej i en graf. | Undersøger to-kant forbundet graf, stærkt forbundet graf, acyklisk graf og topologisk rækkefølge. |
Definition af BFS
Bredde Første søgning (BFS) er den krydsende metode, der anvendes i grafer. Den bruger en kø til opbevaring af de besøgte hjørner. I denne metode er fremhævningen placeret på grafernes hjørner, en toppunkt vælges først, så den bliver besøgt og markeret. Vinklerne ved siden af det besøgte vertex bliver derefter besøgt og opbevaret i køen i rækkefølge. På samme måde behandles de lagrede hjørner en efter en, og deres nærliggende hjørner bliver besøgt. En knude udforskes fuldt ud, før du besøger et andet knudepunkt i grafen, det vil sige, at det først og fremmest overskrider de grundigste uudforskede knuder.
Eksempel
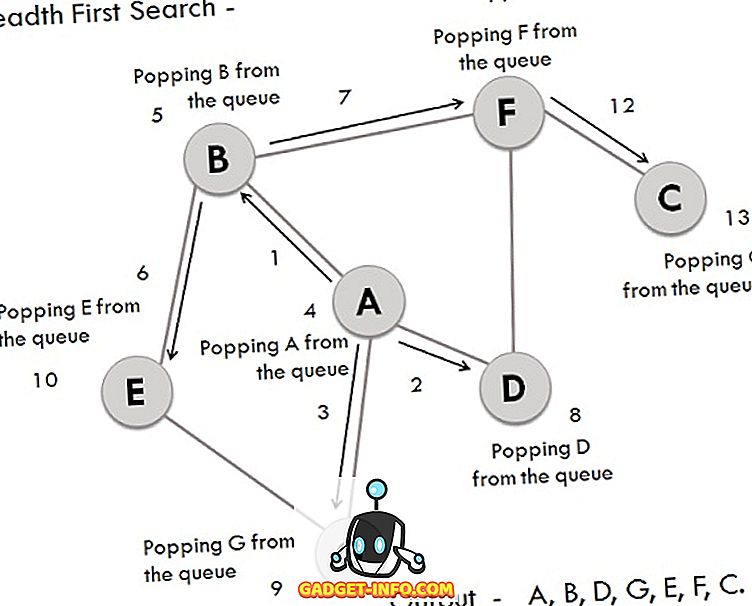
Vi har en graf, hvis hjørner er A, B, C, D, E, F, G. Overvej A som udgangspunkt. De trin der er involveret i processen er:
- Vertex A udvides og lagres i køen.
- Vertikaler B, D og G efterfølgere af A udvides og lagres i køen, mens Vertex A fjernes.
- Nu fjernes B i den forreste ende af køen sammen med lagring af efterfølgerens hjørner E og F.
- Vertex D er i den forreste ende af køen er fjernet, og dens tilsluttede knude F er allerede besøgt.
- Vertex G fjernes fra køen, og den har efterfølger E, som allerede er besøgt.
- Nu fjernes E og F fra køen, og dens efterfølgervertex C bliver krydset og lagret i køen.
- Endelig fjernes også C, og køen er tom, hvilket betyder, at vi er færdige.
- Den genererede output er - A, B, D, G, E, F, C.

BFS kan være nyttigt for at finde ud af om grafen har tilsluttet komponenter eller ej. Og også det kan bruges til at detektere en todelt graf .
En graf er todelt, når grafpunktene er opdelt i to disjoint sæt; ingen to tilstødende hjørner ville opholde sig i samme sæt. En anden metode til kontrol af en todelt graf er at kontrollere forekomsten af en ulige cyklus i grafen. En todelt graf må ikke indeholde ulige cyklus.
BFS er også bedre at finde den korteste vej i grafen kunne ses som et netværk.
Definition af DFS
Dybde første søgning (DFS) krydsning metode bruger stakken til opbevaring af de besøgte hjørner. DFS er den kantbaserede metode og arbejder på rekursiv måde, hvor vinklerne udforskes langs en sti (kant). Undersøgelsen af en node er suspenderet, så snart en anden uudforsket node er fundet, og de dybeste uudforskede knudepunkter krydser først og fremmest. DFS krydser / besøger hvert hjørne nøjagtigt en gang, og hver kant inspiceres nøjagtigt to gange.
Eksempel
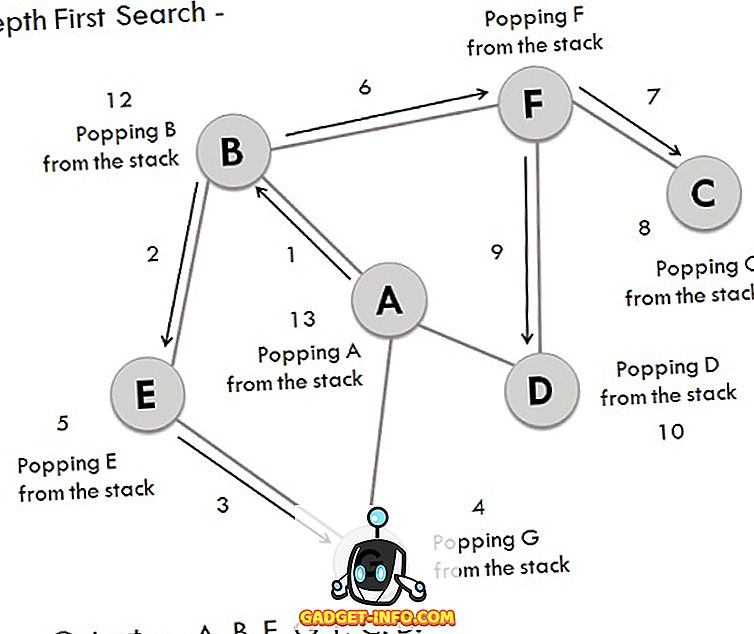
Ligner BFS lader tage den samme graf for at udføre DFS-operationer, og de involverede trin er:
- Overvej A som startpunktet, som udforskes og opbevares i stakken.
- B efterfølgerens vinkel på A er lagret i stakken.
- Vertex B har to efterfølgere E og F, blandt dem alfabetisk E udforskes først og opbevares i stakken.
- Efterfølgeren til vertex E, dvs. G er gemt i stakken.
- Vertex G har to forbundne hjørner, og begge er allerede besøgt, så G er poppet ud fra stakken.
- Tilsvarende fjernede E også.
- Nu er vertex B øverst på stakken, dens anden knudepunkt (vertex) F udforskes og opbevares i stakken.
- Vertex F har to efterfølgere C og D, mellem dem C krydses først og lagres i stakken.
- Vertex C har kun en forgænger, som allerede er besøgt, så den fjernes fra stakken.
- Nu er vertex D forbundet til F besøgt og gemt i stakken.
- Da vertex D ikke har nogen unvisited noder, fjernes D derfor.
- Tilsvarende er F, B og A også poppet.
- Det genererede output er - A, B, E, G, F, C, D.

DFS applikationer omfatter inspektion af to kantforbundne grafer, stærkt forbundet graf, acyklisk graf og topologisk rækkefølge .
En graf kaldes to kanter tilsluttet hvis og kun hvis det forbliver tilsluttet, selvom en af kanterne er fjernet. Denne applikation er meget nyttig i computernetværk, hvor fejlen af et link i netværket ikke vil påvirke det resterende netværk, og det ville stadig være forbundet.
Stærkt forbundet graf er en graf, hvor der skal eksistere en sti mellem det ordnede par af hjørner. DFS bruges i den rettede graf for at søge stien mellem hvert ordnet par af hjørner. DFS kan nemt løse problemer med tilslutning.
Nøgleforskelle mellem BFS og DFS
- BFS er vertex-baseret algoritme, mens DFS er en kantbaseret algoritme.
- Kødatastruktur bruges i BFS. På den anden side bruger DFS stack eller rekursion.
- Hukommelsesplads udnyttes effektivt i DFS, mens rumudnyttelse i BFS ikke er effektiv.
- BFS er optimal algoritme, mens DFS ikke er optimal.
- DFS konstruerer smalle og lange træer. I modsætning hertil konstruerer BFS bredt og kort træ.
Konklusion
BFS og DFS, begge grafnesøgningsteknikker har lignende driftstid, men forskellig rumforbrug, DFS tager lineært rum, fordi vi skal huske enkeltvej med uudforskede noder, mens BFS holder hver node i hukommelsen.
DFS giver dybere løsninger og er ikke optimal, men det fungerer godt, når løsningen er tæt, mens BFS er optimal, der først søger det optimale mål.