Båndbredden, der anvendes i UMA'en til hukommelsen, er begrænset, da den bruger en enkelt hukommelsescontroller. Det primære motiv for fremkomsten af NUMA-maskiner er at forbedre den tilgængelige båndbredde til hukommelsen ved at bruge flere hukommelsescontrollere.
Sammenligningstabel
| Grundlag for sammenligning | UMA | NUMA |
|---|---|---|
| Grundlæggende | Bruger en enkelt hukommelsescontroller | Flere hukommelsescontroller |
| Type af brugte busser | Single, multiple og crossbar. | Træ og hierarkisk |
| Hukommelse adgangstid | Lige | Ændringer i henhold til afstanden til mikroprocessoren. |
| Egnet til | Generelle formål og tidsdeling applikationer | Realtids- og tidskritiske applikationer |
| Hastighed | Langsommere | Hurtigere |
| båndbredde | Begrænset | Mere end UMA. |
Definition af UMA
UMA (Uniform Memory Access) -systemet er en delt hukommelsesarkitektur for multiprocessorerne. I denne model anvendes en enkelt hukommelse og adgang til alle processorer præsenterer multiprocessorsystemet ved hjælp af sammenkoblingsnetværket. Hver processor har samme hukommelsesadgangstid (latency) og adgangshastighed. Det kan ansætte en af enkeltbussen, flere busser eller tværstangskontakter. Da det giver en afbalanceret delt hukommelsesadgang, er den også kendt som SMP (Symmetrisk multiprocessor) systemer.
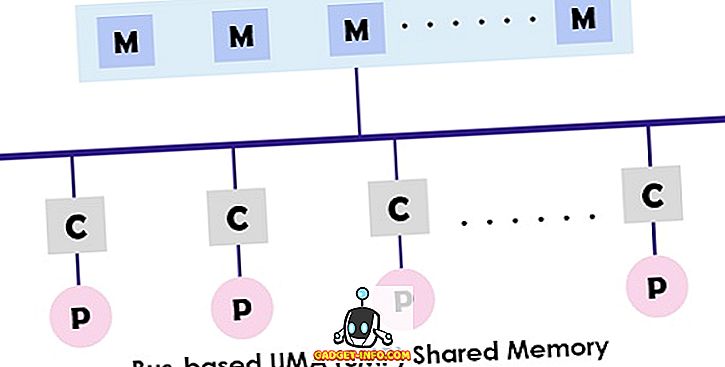
Det typiske design af SMP'en er vist ovenfor, hvor hver processor først forbindes til cachen, da cachen er bundet til bussen. Endelig er bussen tilsluttet hukommelsen. Denne UMA-arkitektur mindsker argumentet for bussen ved at hente instruktionerne direkte fra den individuelle isolerede cache. Det giver også en lige sandsynlighed for læsning og skrivning til hver processor. De typiske eksempler på UMA-modellen er Sun Starfire-servere, Compaq alpha-server og HP v-serien.
Definition af NUMA
NUMA (ikke-ensartet hukommelsesadgang) er også en multiprocessormodel, hvor hver processor er forbundet med dedikeret hukommelse. Men disse små dele af hukommelsen kombinerer at danne et enkelt adresserum. Det vigtigste punkt at overveje her er, at modsætning til UMA, afhænger adgangstidspunktet for hukommelsen på den afstand, hvor processoren er placeret, hvilket betyder varierende hukommelseadgangstid. Det giver adgang til enhver af hukommelsesstedet ved hjælp af den fysiske adresse.
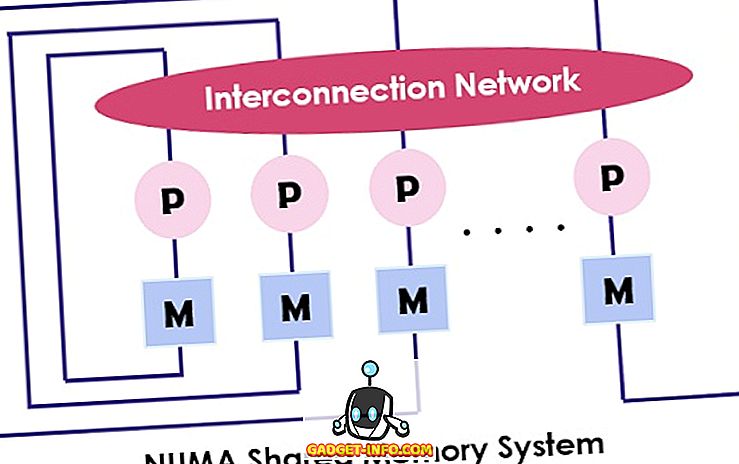
Som nævnt ovenfor er NUMA-arkitekturen beregnet til at øge den tilgængelige båndbredde til hukommelsen, og for hvilken den bruger flere hukommelsescontrollere. Det kombinerer mange maskinkerner i " knudepunkter ", hvor hver kerne har en hukommelsescontroller. For at få adgang til den lokale hukommelse i en NUMA-maskine, henter kernen hukommelsen, der styres af hukommelsescontrolleren, ved hjælp af noden. Mens der er adgang til fjernhukommelsen, der håndteres af den anden hukommelsescontroller, sender kernen hukommelsesanmodningen gennem forbindelseslinks.
NUMA-arkitekturen bruger træ- og hierarkiske busnetværk til at forbinde hukommelsesblokkene og processorerne. BBN, TC-2000, SGI Origin 3000, Cray er nogle af eksemplerne på NUMA-arkitekturen.
Nøgleforskelle mellem UMA og NUMA
- UMA-modellen (delt hukommelse) bruger en eller to hukommelsescontrollere. I modsætning hertil kan NUMA få flere hukommelsescontrollere til at få adgang til hukommelsen.
- Enkle, flere og tværstangsbusser anvendes i UMA-arkitekturen. Omvendt bruger NUMA hierarkiske og træ type busser og netværksforbindelse.
- I UMA er hukommelsesadgangstiden for hver processor den samme, mens i NUMA ændres hukommelsesadgangstiden, når afstanden fra hukommelsen fra processoren ændres.
- Generelle formål og tidsdeling applikationer er egnede til UMA maskiner. I modsætning hertil er den relevante applikation for NUMA realtid og tidskritisk centrisk.
- De UMA-baserede parallelle systemer arbejder langsommere end NUMA-systemerne.
- Når det kommer til båndbredde UMA, har begrænset båndbredde. Tværtimod har NUMA båndbredde mere end UMA.
Konklusion
UMA-arkitekturen giver den samme generelle latens til processorerne, der har adgang til hukommelsen. Dette er ikke særlig nyttigt, når den lokale hukommelse er tilgængelig, fordi latensen ville være ensartet. På den anden side havde hver processor i sin NUMA sin dedikerede hukommelse, hvilket eliminerer latensen, når den lokale hukommelse er tilgængelig. Latensen ændres som afstanden mellem processoren og hukommelsesændringer (dvs. ikke-ensartet). NUMA har dog forbedret ydeevnen i forhold til UMA-arkitekturen.